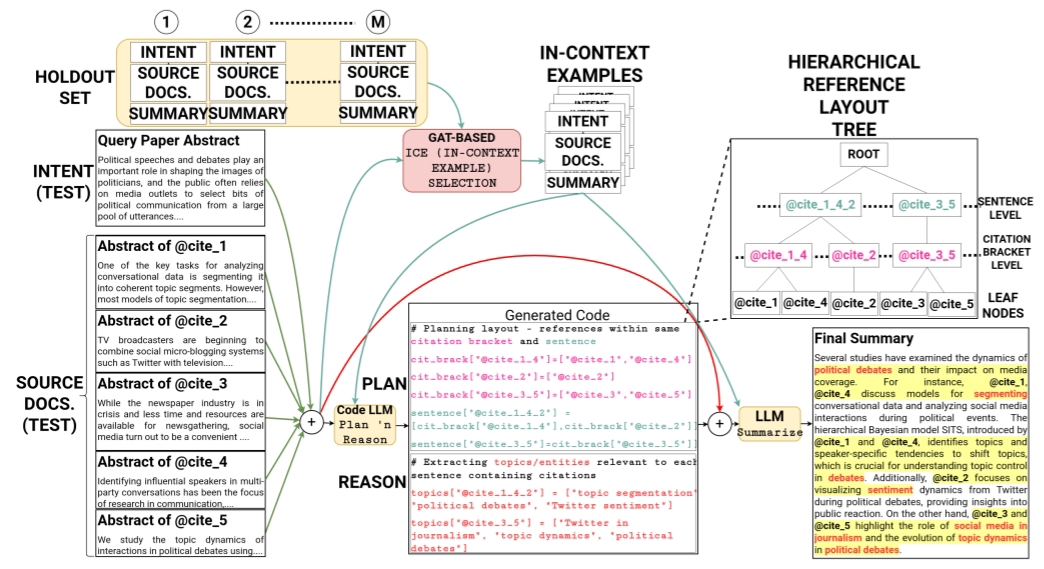
Our Proposed Framework: MiDAS-PRo
This Figure shows the MiDAS-PRo Framework for Multi-Document Summarization.
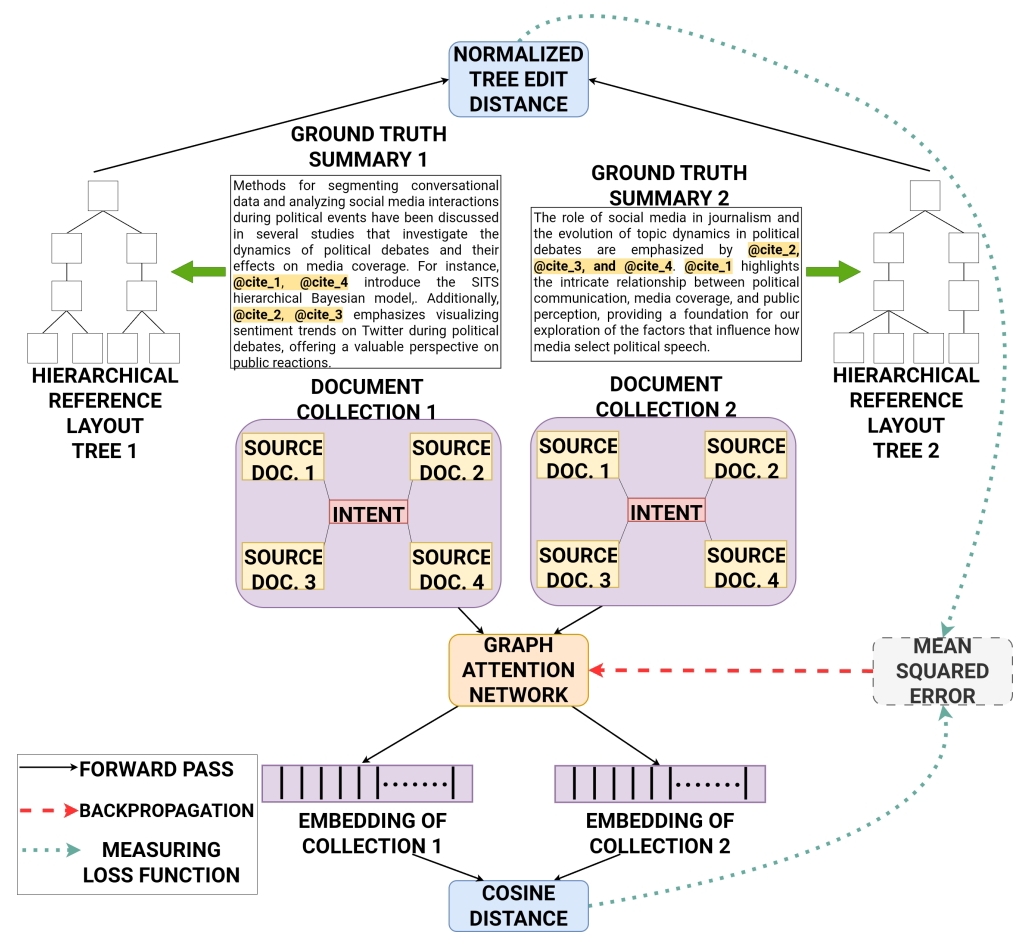
In-Context Example Selection
Training GAT module for ICE (In-Context Example) Selection
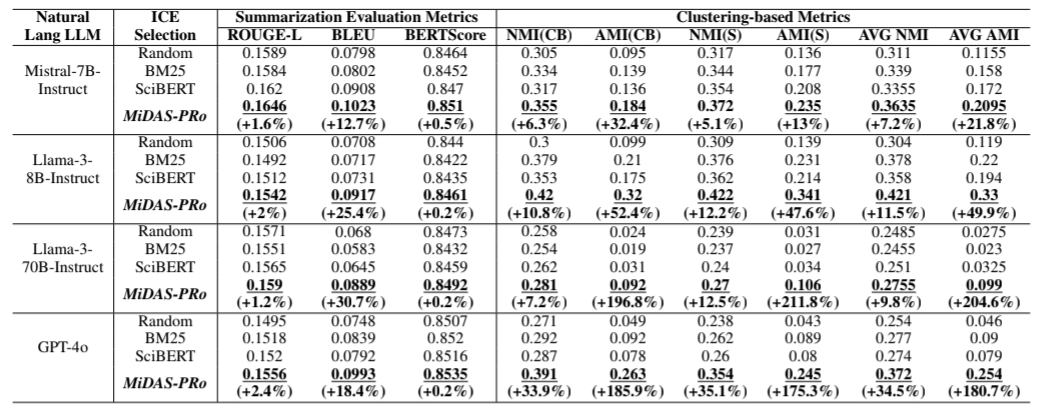
1-Shot Results on Multi-XScience Dataset
1-Shot Results of Natural Language LLMs combined with different ICE Selection Methods compared to MiDAS-PRo
on Multi-XScience. Underlined values correspond to metrics where MiDAS-PRo gives signifcant improvement (p < 0.05)
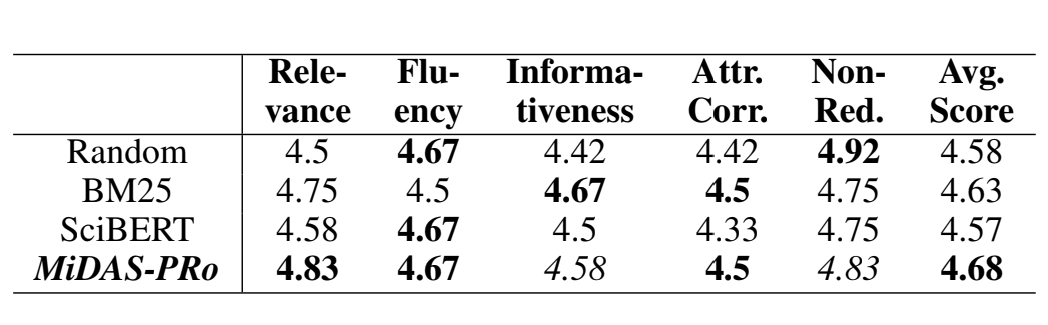
1-Shot Results on MiDAS Dataset
1-Shot In-Context Results of GPT-4o combined with different In-Context Example (ICE) Selection Methods compared to MiDAS-PRo on MiDAS. Results in bold and italic are the best and the second-best results respectively

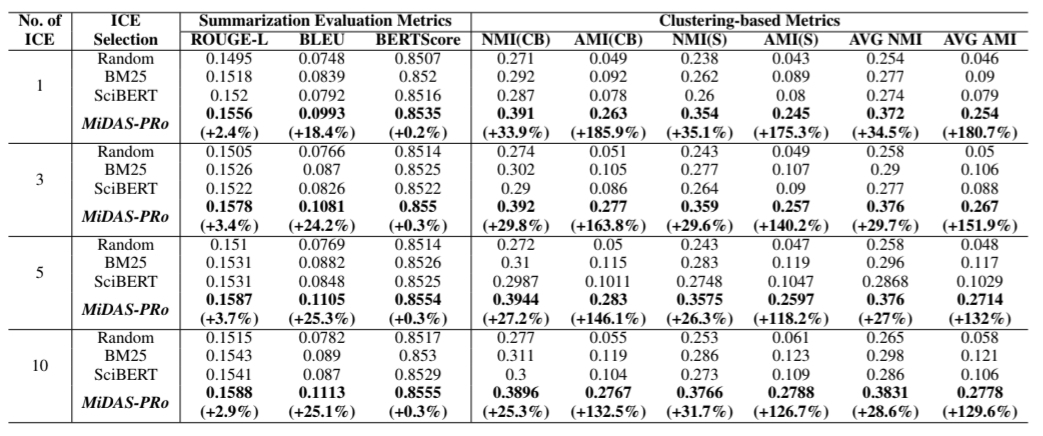
K-shot Results
K-Shot In-Context Results (K = 1, 3, 5, 10) of GPT-4o combined with different ICE Selection Methods compared to MiDAS-PRo on Multi-XScience. MiDAS-PRo gives signifcant improvement (p < 0.05) compared to baselines
Ablation Analysis
Ablation Analysis of MiDAS-PRo when applied on Llama-3-8B-Instruct (GPT-4o is used for generating the code).

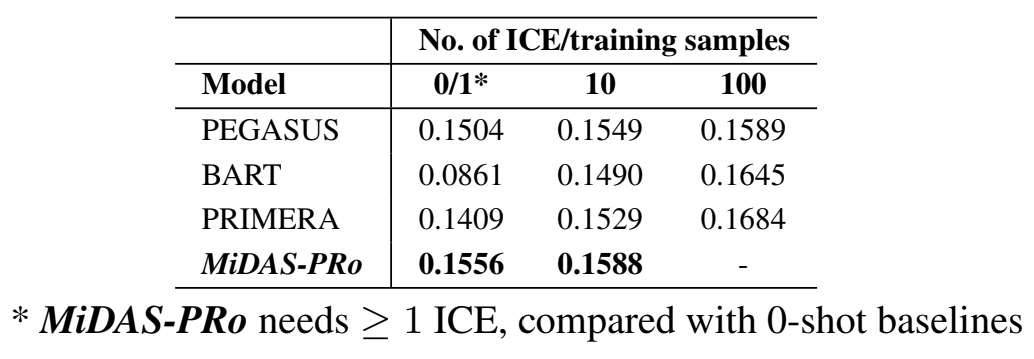
MiDAS-PRo Vs. Baselines
Comparison of MiDAS-PRo (with GPT-4o back-bone) with other Multi-Doc Summarization Baselines.
Human Evaluation
Human Evaluation of MiDAS-PRo